Machine Learning: Iris Flower Classification
Training an SVM classifier with a non-linear kernel (RBF) on the Iris dataset (Fisher, 1936), using scikit-learn in Python 3.13, as part of COMP3330 - Machine Intelligence.
1 Introduction
The Iris flower dataset is one of the most-cited resources in machine-learning research per the UCI machine learning repository [1] due to its utility as a classification problem: given measurements of the sepal and flower petal of a plant, predict whether the specimen belongs to one of three species: The Iris setosa, Iris versicolor, or Iris virginica. The task then is to learn a decision function that generalises from limited, partly overlapping data while controlling the potential for over-fitting, a scenario which mimics many real-world problems when dealing with Machine Intelligence.
2 Methodology
Model Choice
Per the specifications on the UCI repository, we know that the dataset contains 150 instances, each described by four real-valued measurements and labelled as one of three Iris species. Of note, Iris setosa is linearly separable, while the other two species contain non-linear overlap. In this scenario, a soft-margin Support Vector Machine (SVM) with an RBF kernel can reject over-fitting using only a handful of tuning parameters [2] [3].
Pre-processing
The chosen model is sensitive to the relative scale of input dimensions due to its exponentiality:
\[K(x_i,x_j)=exp\left(-\frac{||x_i-x_j||}{2\sigma^2}\right),\rightarrow\text{ Squared Euclidean distance }\gamma=\frac{1}{2\sigma^2}\] \[\therefore K(x_i,x_j)=exp\left(-\gamma||x_i-x_j||^2\right)\]Additionally, the SVM regularisation parameter C determines the trade-off between margin width and classification error. We can tune this parameter by splitting the training data and validation data and performing 5-fold cross validation. The prior standardization will apply only to the training set, of which a train-test split of 80-20 is chosen as an arbitrary starting point to be refined later if required.
3 Implementation
Table 1: Environment and Tools for SVM-RBF-Iris Implementation.
| Component | Details |
|---|---|
| Language Used | Python 3.13.3 (SysEnv) + PyCharm 2025.1.1 IDE |
| ML Library | scikit-learn 1.7.0rc1 (using sklearn namespace) |
| Dataset | Iris (Fisher, 1936) |
| Supporting Libraries | pandas 2.2.3, matplotlib 3.10.3, dependencies for sci-kit learn, PyQt6 6.9.0 to generate graphs |
| Training Method | Training performed on CPU |
| Gen AI Usage | ChatGPT 4o assisted code generation to use correct scikit libraries, parse correct function parameters, and generate 2D Decision-Surface plot [4] |
Using Python, the Iris dataset is loaded into a pandas dataframe where features 𝑋 are separated from labels 𝑦, and appropriately categorized. The train-test sets are split 80-20, and the SVM classifier is implemented via the SVC function in scikit-learn within the pipeline function where the validation set is standardised to zero mean, unit variance.
We then perform a 5-fold cross-validation, and setup a Python dictionary to contain the range of regularisation and margin width hyperparameters (denoted parameter grid in code). Finally, we call GridSearchCV and parse the pipeline, parameter grid, and cross-validation to perform an exhaustive search (thus, not utilising any metaheuristic optimisations), testing every pair of (𝐶, 𝛾) to provide the highest accuracy. This grid data is then fit onto the training data set.
You can find the dataset and final version of the code on GitHub.
A minor issue that exposed itself early on relates to the Iris dataset itself, where there were two empty rows at the end of the file. These were removed manually and did not require any changes to the code once the issue was discovered. Beyond that, many of the libraries within the scikit-learn module contain a huge amount of documentation which is excellent to read through, however due to personal time crunch and unfamiliarity with the module, Gen AI (ChatGPT 4o) was consulted to help translate the established methodology into working Python code. The code was then manually reviewed and refactored to include more descriptive variable names and verbose commenting that outlines each step in the process. As a result, ChatGPT 4o made three executive decisions within the code that I had not considered, but kept as they made sense given the size of the dataset and scope of the problem:
- The range of regularisation 𝐶, and margin width 𝛾.
- Stratified cross-validation.
- Shuffle each classes samples during cross-validation.
The code generated did not contain any significant bugs or errors, however there was an issue where plots would not generate unless the PyQt6 package was installed. Please keep this in mind if you intend on running .py file yourself.
4 Results
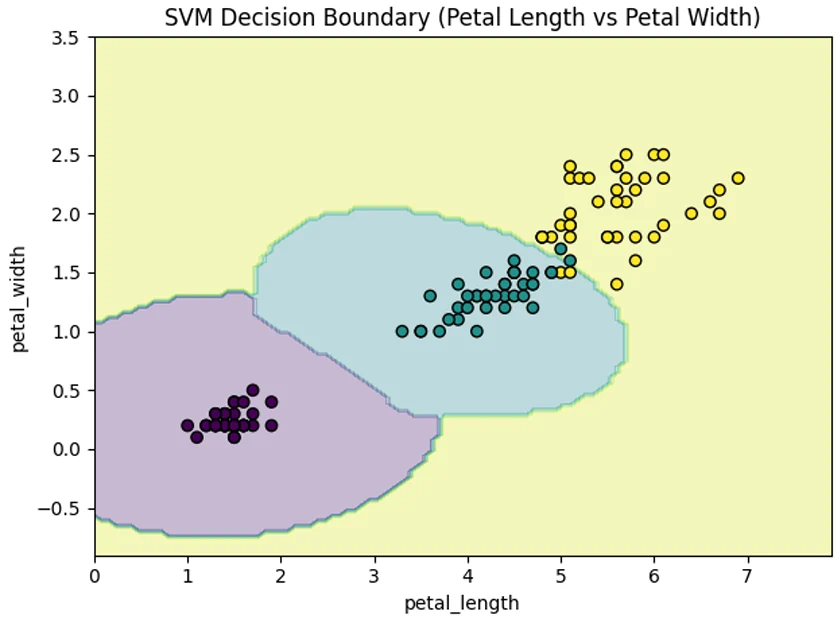 Figure 1: 2D Decision-Surface of petal width vs petal length, with SVM (RBF) overlay
Figure 1: 2D Decision-Surface of petal width vs petal length, with SVM (RBF) overlay
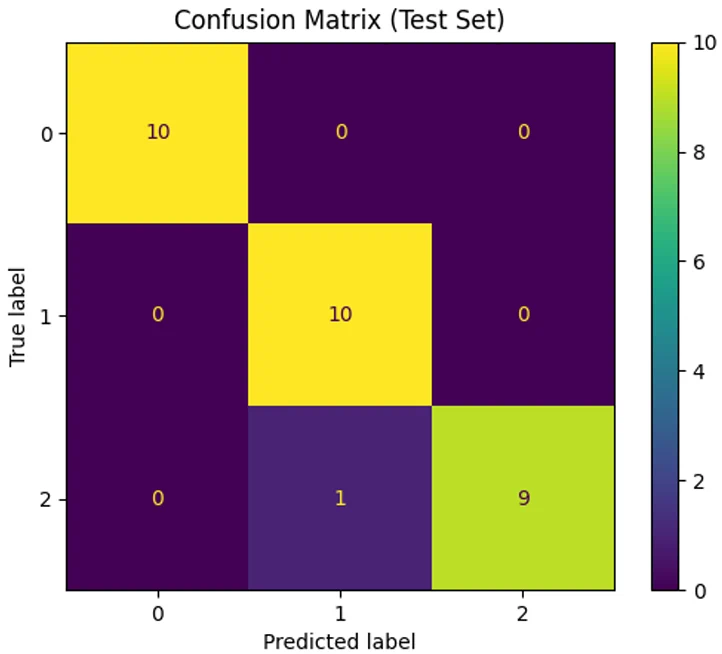 Figure 2: Confusion Matrix of test dataset with estimated best model
Figure 2: Confusion Matrix of test dataset with estimated best model
Table 2: Results from evaluating the best model on unmodified test data set.
| Metric | Result |
|---|---|
| Best hyperparameters | C = 1, gamma = 1 |
| Test accuracy | 0.967 |
| Macro-F1 score | 0.967 |
| Support vectors per class | [13 21 23] |
Discussion
Table 3: Mapping of integer label to name of Iris.
| Integer Label | Iris Type |
|---|---|
| 0 | Iris-setosa |
| 1 | Iris-versicolor |
| 2 | Iris-virginica |
We see from the confusion matrix that a single Iris virginica sample was mis-classified as an Iris versicolor. This confirms the test accuracy reported by Python, and the historical performance data shown in the UCI repository [1].
\[Accuracy: \frac{\left(10+10+9\right)}{30}=0.967\] \[Precision: \frac{10}{11}=0.91\]The confusion will lie in the overlapping pair of samples shown in Figure 1. Further tuning may tighten the boundary between the Iris species, but at the risk of over-fitting. Still, the SVM-RBF is able to handle partial non-linearity with minimal error and perfectly classifies two out three Iris species.
5 Conclusion
Training an SVM-RBF on the Iris dataset achieved 96.7% accuracy and a 91% micro-precision for one of three Iris species. The confusion matrix demonstrates perfect classification of Iris setosa and Iris versicolor, with a single misclassification of the partially overlapping Iris virginica. An 80-20 train-test split was selected which showcases the SVM maximisation principle [2] holds true with good generalisation for such a compact model.
Regarding ethical concerns, the dataset contains no personal or otherwise sensitive information attributes and poses no risk to privacy, though one could make the statement that the sample size being so small is irresponsible if the model is meant to generalise a wide range of plants or be resilient to measurement noise.
Future Work
Extending the dataset to include more attributes of Iris species could help with improving the multi-dimensional classification of the SVM and allow it to better capture non-linearly separable data. Alternatively, Neural Network classification that can adapt feature-by-feature interaction and approximate a more suitable decision surface than the SVM-RBF may improve the precision.
References
[1] R. Fisher, “Iris,” UCI Machine Learning Repository, 1936. [Online]. Available: https://doi.org/10.24432/C56C76.
[2] Wikipedia, “Support vector machine,” 2025. [Online]. Available: https://en.wikipedia.org/wiki/Support_vector_machine.
[3] Wikipedia, “Radial basis function kernel,” 2025. [Online]. Available: https://en.wikipedia.org/wiki/Radial_basis_function_kernel.
[4] C. 4o, “Used for code generation of functions within the scikit-learn Machine Learning module with respect to established methodology.,” Open AI, 2025. [Online]. Available: https://www.chatgpt.com.